
形態素解析は自然言語処理の一部であり、テキストデータの加工をより理解するための不可欠な手法です。形態素解析をPythonで実現するためには、MeCabというツールが非常に重要な役割を果たします。
MeCabは形態素解析のための効率的なライブラリで、テキストを粒状に分析することができます。そして、その結果を用いて感情分析やテキストマイニングなどの高度な操作を行うことも可能です。
一方で、プログラミングの初心者やMeCabについて詳しくない方々にとっては、「MeCabとは何なのか?」「どのようにPythonと組み合わせて使うのか?」といった疑問が生じることでしょう。
本記事では、MeCabの基本的な概要から実画像を用いたインストール方法、Pythonとの組み合わせ方、そして実践的な形態素解析までを初心者向けに詳しく解説します。
おさらい:形態素解析とは?
形態素解析とは、テキストデータを形態素(日本語の最小単位)に分割し、それぞれの形態素がどのような種類の単語(名詞、動詞、形容詞など)であるかを特定するプロセスのことを指します。
文章を分割することで、テキストデータから詳細な情報を抽出し、その内容を理解することが可能となります。
たとえば、「私は公園でジョギングをします」という文を形態素解析すると、「私/名詞」「は/助詞」「公園/名詞」「で/助詞」「ジョギング/名詞」「を/助詞」「します/動詞」のように分割・分類されます。
私は公園でジョギングをします
私 は 公園 で ジョギング を します
MeCabとは?概要と用途
MeCabは形態素解析を行うためのオープンソースソフトウェアで、特に日本語テキストの形態素解析において優れた性能を発揮します。MeCabは、多くの自然言語処理ライブラリと組み合わせて使用され、テキストマイニングや感情分析などの応用分野で広く利用されています。
この章では、MeCabの概要と用途について説明します。
MeCabの概要
MeCabは、C++で開発された日本語形態素解析ライブラリで、その精度と速度から多くの自然言語処理専門家に支持されています。また、Python等の多くのプログラミング言語との連携も容易なため、Mecabは各種の自然言語処理タスクで頻繁に活用されます。
MeCabの用途
MeCabはその精度と速度から、幅広い用途で活用されています。特に自然言語処理の分野では欠かせないツールとなっています。具体的な用途をいくつか挙げてみましょう。
- テキストマイニング:形態素解析を利用することで、テキストから有用な情報を抽出したり、特定のパターンを発見したりします。ユーザーレビューやSNSの投稿など、大量のテキストデータから意味のある情報を引き出すことが可能になります。
- 感情分析(センチメント分析):形態素解析を利用してテキストを分割し、その中から感情を示す単語やフレーズを抽出します。これを基に、テキストの著者がポジティブな感情を持っているのか、ネガティブな感情を持っているのかを判断します。
- 機械翻訳:形態素解析を使用することで、文を意味のある単位に分割し、その各部分を他の言語の単語やフレーズに翻訳します。
- 音声認識:形態素解析を活用して、音声データからテキストデータへの変換を行います。具体的には、音声からテキストを生成した後、形態素解析を用いて文を分割し、それぞれの単語やフレーズを理解します。
これらの用途は一部に過ぎません。その他にも、MeCabは自然言語処理のさまざまなタスクにおいて、形態素解析の基本的なステップとして活用されます。
MeCabのインストール手順
MeCabのインストールは本体のインストールだけでなく、環境変数の設定、Python用のラッパーライブラリのインストール、そして辞書のインストールという複数のステップが必要です。
この章では、これらすべてのステップを実画像を用いて丁寧に説明します。
MeCabのインストール
まずはMeCab本体のインストールから始めましょう。以下の手順に従ってください。

①GitHubのサイトにアクセスして、mecab-64-0.996.2.exe をクリック
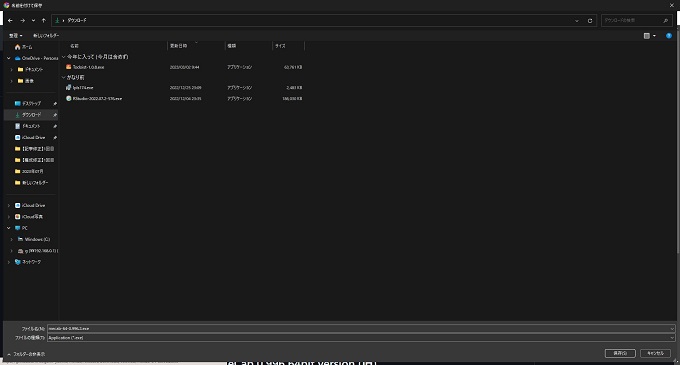
②インストーラーのダウンロード先を指定して、ダウンロード
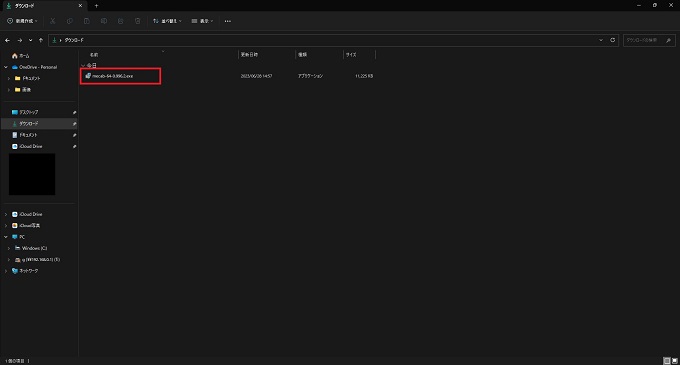
③インストーラーをダブルクリックで実行
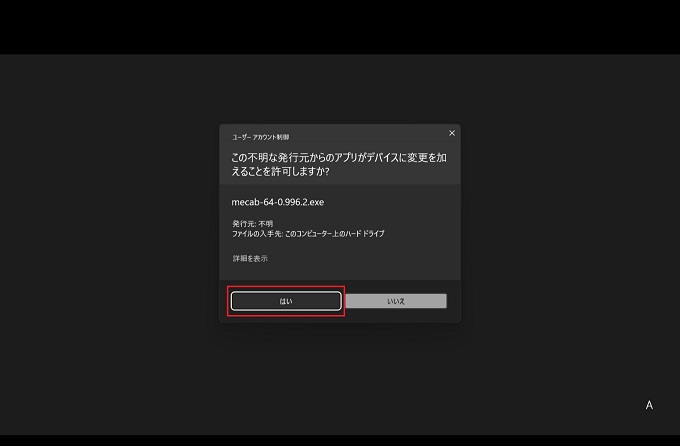
④はいをクリック
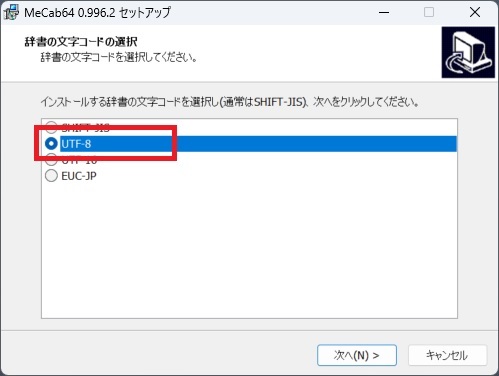
⑤インストールする文字コードはUTF-8を選択して、次へをクリック
SHIFT-JISは主にWindows環境で使われる日本語の文字コードであり、日本で広く使用されています。一方、UTF-8は多言語に対応したユニバーサルな文字コードで、現代のウェブや多くのプログラミング環境で主流となっています。
特にプログラミングにおいては、文字コードの不一致が原因でエラーが発生することが多いため、互換性の高いUTF-8を選択することが多いです。また、Python 3以降では、ソースコードのデフォルトのエンコーディングがUTF-8になっています。
このため、Pythonとの互換性を考慮すると、UTF-8を選択するのが一般的です。

⑥同意するを選択して、次へをクリック
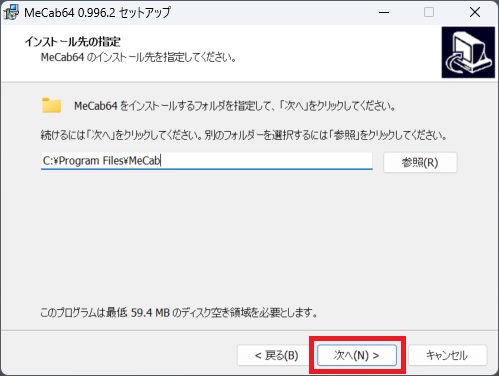
⑦特に理由がなければデフォルトのままで、次へをクリック
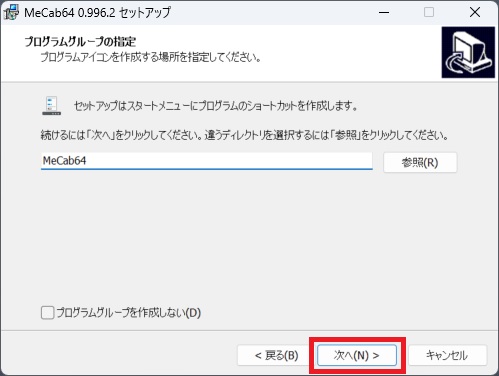
⑧デフォルトのままで、次へをクリック
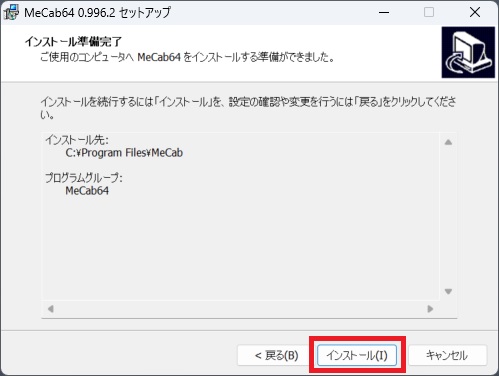
⑨インストールをクリック
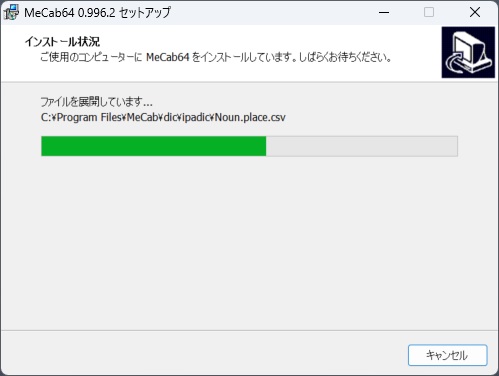
⑩インストールが開始される

⑪はいをクリック
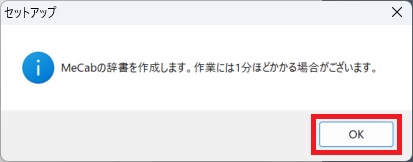
⑫OKをクリック
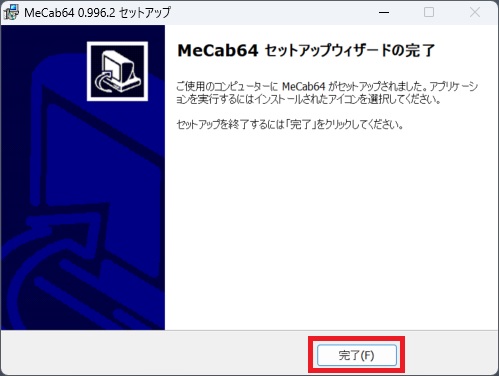
⑬完了をクリック
環境変数の設定(パスの設定)
次に、システムがMeCabを見つけられるように、環境変数にMeCabのインストール先を追加する設定を行います。具体的な手順は、使用しているオペレーティングシステムによって異なりますが、ここではWindowsを例に説明します。

①タスクバー内の検索枠に「sysdim.cpl」と入力し、Enterキーを押下

②システムのプロパティが開くため、詳細設定をクリック

③環境変数をクリック
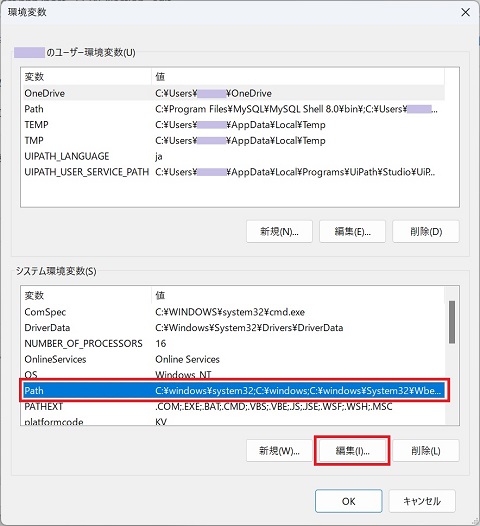
④下段のシステム環境変数内のPathを選択し、編集をクリック

⑤新規をクリック

⑥MeCabのインストール先フォルダパスを調べる
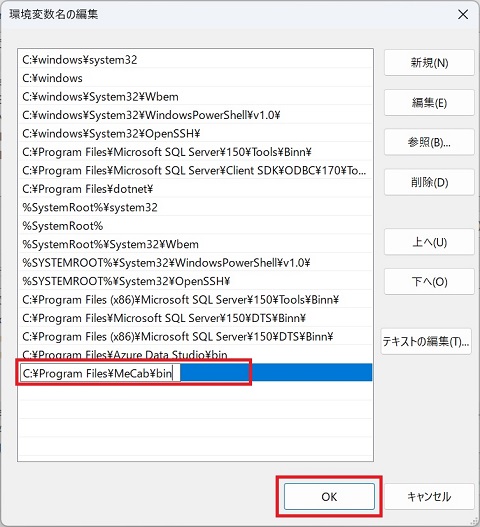
⑦MeCabのインストール先フォルダパスを入力し、OKをクリック
Python用のラッパーライブラリのインストール
PythonとMeCabを連携させるためには、Python用のラッパーライブラリをインストールする必要があります。これにはPythonのパッケージ管理システムであるpipを使用します。下記のコマンドを実行します。
pip install mecab-python-windows辞書のインストール
MeCabをPythonで利用するためには、形態素解析に必要な辞書をインストールする必要があります。ここではunidic-liteというライトバージョンのUniDic辞書をインストールします。下記のコマンドを実行します。
pip install unidic-lite以上の手順により、PythonからMeCabを使用するための準備が整います。今後はPythonプログラム内からMecabの形態素解析機能を呼び出すことができます。
なお、Pythonのバージョンや環境によっては、若干手順が異なる場合がありますので、それぞれの公式ドキュメンテーションを参照してください。
PythonとMeCabの使い方と形態素解析の手順
PythonとMeCabを連携させることで、形態素解析のプロセスをコーディングで行うことができます。あらゆるテキストデータに対して自由に解析を実施することが可能となります。
この章では、MeCabの使い方の基本的な手順から、実際の形態素解析までの手順を説明します。
形態素解析の基本的な手順
形態素解析は、以下の手順で行います。
- MeCabのインスタンスを作成します。
- 解析したいテキストをMeCabに渡します。
- MeCabはテキストを形態素に分割し、それぞれの品詞情報とともに返します。
これをPythonのコードで表すと以下のようになります。
import MeCab
# Mecabのインスタンスを作成
m = MeCab.Tagger()
# 解析したいテキスト
text = "私は公園でジョギングをします"
# 形態素解析を実行
result = m.parse(text)
# 結果の出力
print(result)実践:MeCabを使用した形態素解析
では、実際の文章を用いて形態素解析を実施してみましょう。ここでは、前述した“私は公園でジョギングをします”という文を対象に解析を行います。
import MeCab
# Mecabのインスタンスを作成
m = MeCab.Tagger()
# 解析したいテキスト
text = "私は公園でジョギングをします"
# 形態素解析を実行
result = m.parse(text)
# 結果の出力
print(result)上記のコードを実行すると、下記のような出力が得られます。
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
公園 名詞,一般,*,*,*,*,公園,コウエン,コーエン
で 助詞,格助詞,一般,*,*,*,で,デ,デ
ジョギング 名詞,サ変接続,*,*,*,*,ジョギング,ジョギング,ジョギング
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
します 動詞,自立,*,*,サ変・スル,基本形,する,シマス,シマス
EOS
“EOS”はEnd Of Sentenceの略で、文の終わりを意味します。これらの出力から、各単語がどのような品詞に分類されたかが分かります。
PythonとMeCabを利用した応用的な形態素解析
形態素解析はその本質的な機能を超えて、さまざまな応用的なテキスト解析に用いられます。
中でも、感情分析やテキストマイニングは、企業が顧客の声を理解したり、大量のテキストデータから有用な情報を引き出すために広く活用されています。この章では、それらの応用例について説明します。
感情分析の基本的な手法
感情分析(またはセンチメント分析)とは、テキストに表現された感情(ポジティブ、ネガティブなど)を機械的に把握する技術です。たとえば、顧客からのフィードバックやソーシャルメディアの投稿などを分析して、その感情を数値化し、顧客満足度の改善点を見つけるなどに使われます。
感情分析では形態素解析が大きな役割を果たします。文中の単語(形態素)がポジティブな意味を持つのか、ネガティブな意味を持つのか、そのバランスによって、全体の感情が判断されるからです。
下記に、PythonとMeCabを使用した感情分析の基本的な手順を紹介します。
- 形態素解析でテキストを単語に分割します。
- 分割した単語がポジティブな単語リストに含まれるか、ネガティブな単語リストに含まれるかを確認します。
- ポジティブな単語とネガティブな単語の数を比較し、そのテキストが全体としてポジティブな感情を持つのか、ネガティブな感情を持つのかを決定します。
この感情分析の手法は、より高度な自然言語処理の手法(深層学習等)と組み合わせることで、精度を高めることが可能です。
テキストマイニングの基本的な手法
テキストマイニングは、大量のテキストデータから有用な情報を抽出し、その情報を分析する技術です。形態素解析はテキストマイニングの初期ステップであり、テキストデータを単語レベルに分解して、各単語の頻度や関連性、パターンを解析します。
下記に、PythonとMeCabを使用したテキストマイニングの基本的な手順を紹介します。
- 形態素解析でテキストを単語に分割します。
- 各単語の頻度をカウントします。これは、どの単語がテキスト全体でよく使われているかを把握するのに効果的です。
- 単語の出現パターンや関連性を分析します。これには共起分析(二つの単語が一緒に出現する頻度を調べる分析)などがあります。
- 得られた情報を用いて、テキストの傾向やパターンを把握します。
このように、MeCabとPythonを活用することで、テキストデータに隠された情報を効果的に引き出すことが可能となります。
今回の2つの応用例は、自然言語処理のビジネス活用をイメージしやすい事例です。
現状、AIは広くビジネスに浸透するまでには至っていませんが、大量のレビュー・アンケート結果から顧客の満足度を測ったり、重要ワードを抽出したりすることが、いかに高い価値を生み出すのかは明らかでしょう。
たとえば、Amazonのユーザーレビューをご覧ください。ipadであれば、「指紋認証」や「動画視聴」などの単語がトピックとして表示されています。つまり、それらはユーザーの関心が高いキーワードです。
MeCabが誰でも使えるという環境は、どの会社でもビジネスに自然言語処理を活用できる、と同義なのです。
あとがき
この記事では、日本語形態素解析ライブラリであるMeCabの概要からインストール手順、そしてPythonとの連携による形態素解析の手法まで詳細に説明しました。Pythonで自然言語処理を行う際の重要なツールとして、MeCabはその精度と速度から広く利用されています。
形態素解析は一見難しそうなテーマですが、適切なライブラリを利用すれば、誰でも簡単に扱うことができます。今回、学習した知識を活用して、PythonとMeCabを用いた形態素解析に挑戦してみてはいかがでしょうか。
また、PythonとMeCabを使った形態素解析は、感情分析やテキストマイニングといった応用的な分野にも適用可能です。これらの分野は、ビジネスや研究において大きな価値を持つ可能性があります。形態素解析の基本的なスキルを身につけることで、より広範な自然言語処理の世界が開けるでしょう。